Apache Spark Scheduling mit Kubernetes
Apache Spark ist wohl aktuell die beliebteste Big Data Engine, um große Datenmengen hochperformant und skalierbar von A nach B zu prozessieren und dabei gegebenenfalls zu analysieren. Dies gilt sowohl für das klassische Batch-Processing als auch für kontinuierliches Stream-Processing basierend auf Events, zum Beispiel unter Einbeziehung von Apache Kafka. Dieser Beitrag behandelt die Koordination und Orchestrierung von Apache Spark Applications (im folgenden „Applications“ genannt) als Cronjobs unter Kubernetes. Die Implementierung und das eigentliche Arbeiten mit Apache Spark Applications soll hier nicht behandelt werden. Dazu gibt es bereits sehr gute Blogs und Tutorials wie zum Beispiel von databricks. Das Processing wird in der Regel über Applications ausgeführt, welche typischerweise in Scala oder Python implementiert und an Apache Spark übermittelt werden. Die Koordination der Workloads innerhalb der Applications werden vom Spark-Master (im folgenden „Master“ genannt) per sogenannten Exekutoren (im folgenden „Executors“ genannt) durchgeführt unter Einbeziehung der zu Verfügung stehenden Spark-Worker (im folgenden „Worker“ genannt). Innerhalb dieser Applications ist es möglich komplexe Transformationen oder Analysen durchzuführen und die Daten entsprechend der Resultate an angeschlossenes System auszuleiten. Im Falle des Datastreamings passiert dies live bzw. in nahezu Echtzeit. Es ist also möglich vom User generierte Daten (z.B. Blogbeiträge oder Kommentare) direkt zu analysieren und entsprechend der Analyse-Ergebnisse zu behandeln. Beispiele hierfür sind das korrekte Einordnen in eine Kategorie durch Hinzufügen von Tags oder sogar die komplette Löschung bzw. Archivierung im Falle von explizitem Inhalt. Gerne werden solche Operationen auch mit AI-Frameworks wie zum Beispiel TensorFlow kombiniert, um entsprechende Ergebnisse herbeizuführen.
Architektur
Apache Spark kann neben dem standalone Betrieb auch innerhalb verschiedener Cloud Umgebungen ausgeführt werden. Hierzu gehören unter anderem Apache Mesos oder Kubernetes. Im Falle der Verwendung von Kubernetes werden sowohl die Worker als auch der Master als Container innerhalb der Kubernetes Pods ausgeführt wie folgendes Schaubild verdeutlicht:
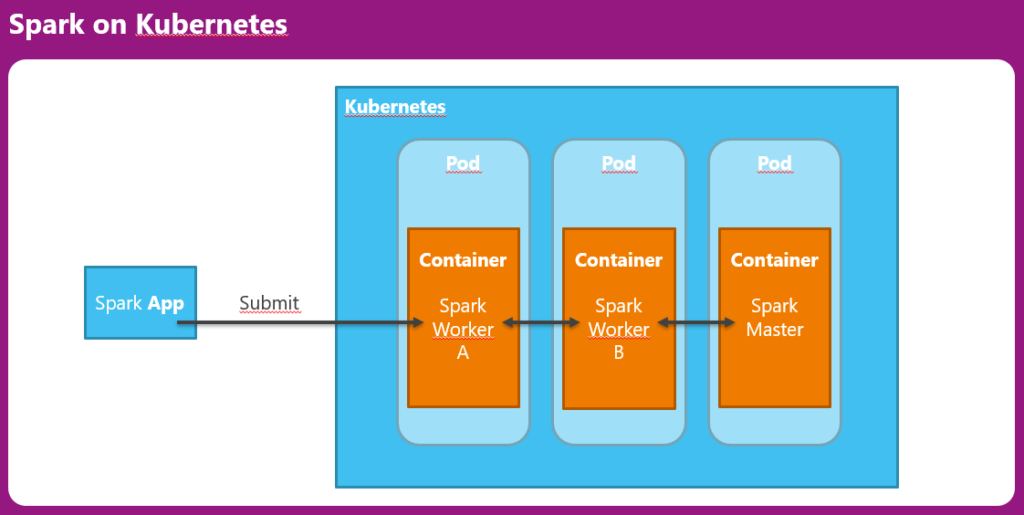
Für Docker liegen zum aktuellen Zeitpunkt mehrere Images von verschiedenen Organisationen vor. Das Image von Bitnami wird von uns sehr gerne aufgrund der Einfachheit der Konfiguration verwendet. Auf Basis dieses Images ist auch unser Beispiel aufgebaut.
Deployment von Master und Worker
Zunächst werden, wie in der vorherigen Darstellung gezeigt, der Master und die zwei Worker auf der Kuberenetes-Instanz durch das Anwenden des Befehles „kubectl apply -f“ mit den entsprechend konfigurierten YAML-Files als Replication Controller deployed:
Spark-Master:
kind: ReplicationController
apiVersion: v1
metadata:
name: qs-spark-master-controller
spec:
replicas: 1
selector:
component: qs-spark-master
template:
metadata:
labels:
component: qs-spark-master
spec:
hostname: qs-spark-master-hostname
subdomain: qs-spark-master-headless
volumes:
- name: "spark-volume"
persistentVolumeClaim:
claimName: "qs-spark"
containers:
- name: qs-spark-master
image: bitnami/spark:3.0.1-debian-10-r65
imagePullPolicy: IfNotPresent
volumeMounts:
- name: "spark-volume"
mountPath: "/code"
ports:
- containerPort: 7077
- containerPort: 8080
env:
- name: SPARK_MODE
value: "master"
resources:
requests:
cpu: 100m
Spark-Worker:
kind: ReplicationController
apiVersion: v1
metadata:
name: qs-spark-worker-controller
spec:
replicas: 2
selector:
component: qs-worker
template:
metadata:
labels:
component: qs-worker
spec:
volumes:
- name: "spark-volume"
persistentVolumeClaim:
claimName: "qs-spark"
containers:
- name: qs-spark-worker
image: bitnami/spark:3.0.1-debian-10-r65
imagePullPolicy: IfNotPresent
volumeMounts:
- name: "spark-volume"
mountPath: "/code"
ports:
- containerPort: 8081
env:
- name: SPARK_MODE
value: "worker"
- name: SPARK_MASTER_URL
value: spark://qs-spark-master:7077
resources:
requests:
cpu: 100m
Die Beschreibung der weiteren benötigten YAML-Konfigurationen wie zum Beispiel für die Services oder für die erforderlichen Volumes, welche über das Volume-Claim „qs-spark“ gesteuert werden, setzen wir hier voraus. Weitere Informationen dazu finden Sie im Fazit weiter unten.
Nach erfolgreicher Anwendung der Konfiguration und nach dem erfolgreichen Hochfahren der Pods in Kubernetes zeigt der Befehl „kubectl get pods | egrep ‚.*(NAME|qs-spark).*‘).*’“ das folgende Listing in Kubernetes:

Dies sollte sich nach kurzer Zeit ebenfalls in der Web-UI des Masters wie im folgenden Screenshot darstellen:
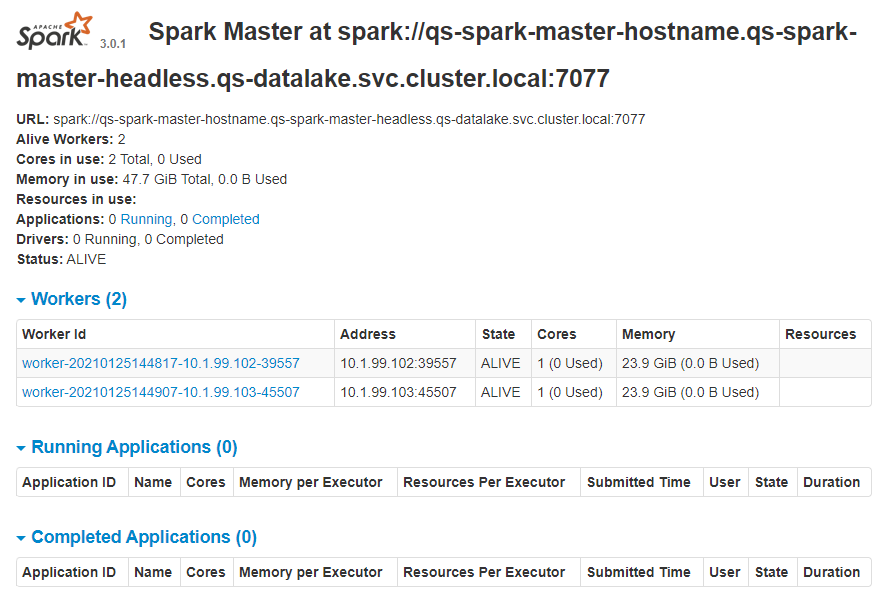
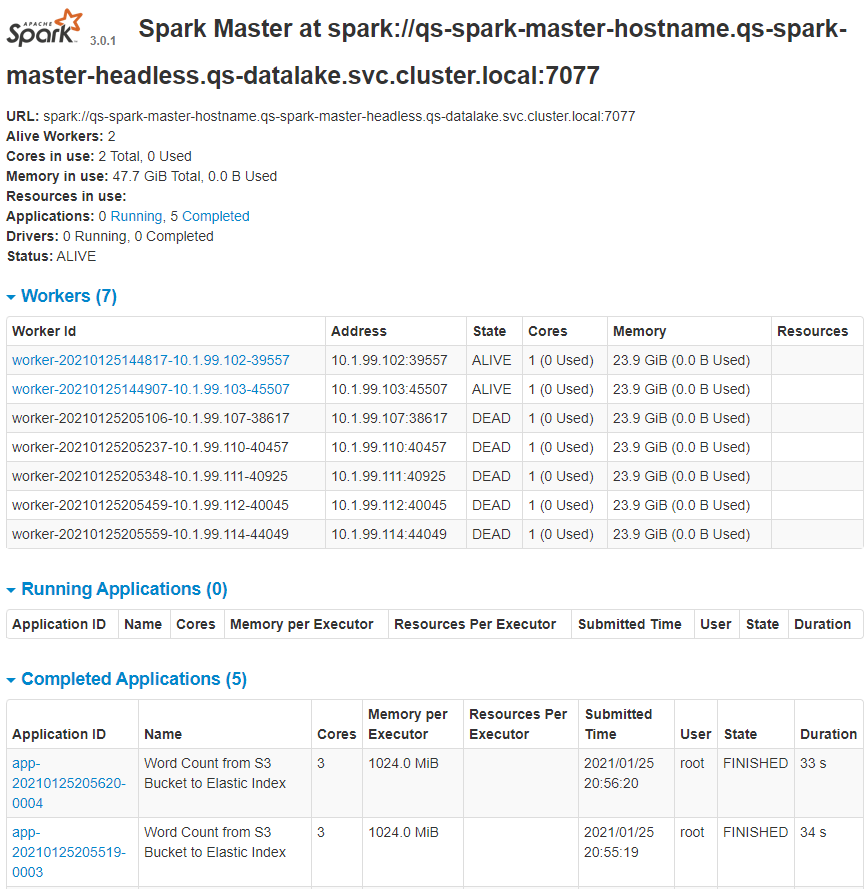
Es ist zu erkennen, dass die zwei konfigurierten Worker korrekt innerhalb des Clusters gefunden werden und bereit sind für die Annahme und für die Abarbeitung von Apache Spark Applications.
Deployment des dynamischen zeitgesteuerten Workers per Kubernetes Job
Es stellt sich nun die Frage wie es möglich ist zeitgesteuert Apache Spark Applications zu starten. Falls Apache Spark innerhalb einer Kubernetes Umgebung zum Einsatz kommt, liegt es nahe für diese Art der Ausführung die native Kubernetes Job-Steuerung zu verwenden. Für die Anlage eines zeitgesteuerten Kubernetes Cronjobs wird ebenfalls ein entsprechendes YAML-File benötigt.
Spark-Job:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: qs-spark-job
spec:
suspend: false
concurrencyPolicy: Forbid
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: qs-spark-job
image: bitnami/spark:3.0.1-debian-10-r65
imagePullPolicy: Always
volumeMounts:
- name: "spark-volume"
mountPath: "/code"
ports:
- containerPort: 8081
env:
- name: SPARK_MODE
value: "worker"
- name: SPARK_MASTER_URL
value: spark://qs-spark-master:7077
envFrom:
- secretRef:
name: qs-es-elastic-user
- secretRef:
name: qs-minio
command:
- "/bin/bash"
- "-c"
- "/opt/bitnami/scripts/spark/entrypoint.sh /opt/bitnami/scripts/spark/run.sh & spark-submit --conf spark.jars.ivy=/code/artifacts --packages com.amazonaws:aws-java-sdk:1.7.4,org.apache.hadoop:hadoop-aws:2.7.7,org.elasticsearch:elasticsearch-hadoop:7.10.0 --master spark://qs-spark-master:7077 /code/s3_read_elastic_write_example.py http://qs-minio:9000 s3a://qs-bucket/ qs-es-http"
resources:
requests:
cpu: 100m
restartPolicy: Never
volumes:
- name: "spark-volume"
persistentVolumeClaim:
claimName: "qs-spark"
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
Nach erfolgreicher Anwendung der Konfiguration und nach dem erfolgreichen Hochfahren der Pods in Kubernetes zeigt der Befehl „kubectl get cronjobs“ das folgende Listing in Kubernetes:

Der konfigurierte CronJob wird also demnach zukünftig jede Minute automatisch von Kubernetes ausgeführt. Der Vorteil hierbei ist, dass beim Start des Kubernetes Cronjobs ein zusätzlicher Pod erzeugt wird. Bei entsprechender Konfiguration unter Beachtung der richtigen Reihenfolge der Bash-Befehle wird vor dem Kommando zur Übermittlung der Apache Spark Application per „spark-submit“ ein weiterer Worker erzeugt und hochgefahren. Dieser wird dann automatisch in die Abarbeitung und die Verteilung der Tasks mit einbezogen. Nach dem Abschluss der Application wird dieser wieder beendet. Zu beachten hierbei ist, dass auf dem Kubernetes Namespace entsprechende Resource Quotas zur Verfügung stehen.
Ausführung
Nach dem Start des Kubernetes Cronjobs taucht in unserem Pod-Listing ein weiterer Pod namens „qs-spark-job-1611607860-dcqtb“ auf:

Wie im Abschnitt „Deployment“ beschrieben ist in der Web-UI des Masters sofort ersichtlich, dass ein 3. Worker hinzugefügt wurde und eine neue Application korrekt erzeugt wurde mit dem State „RUNNING“:
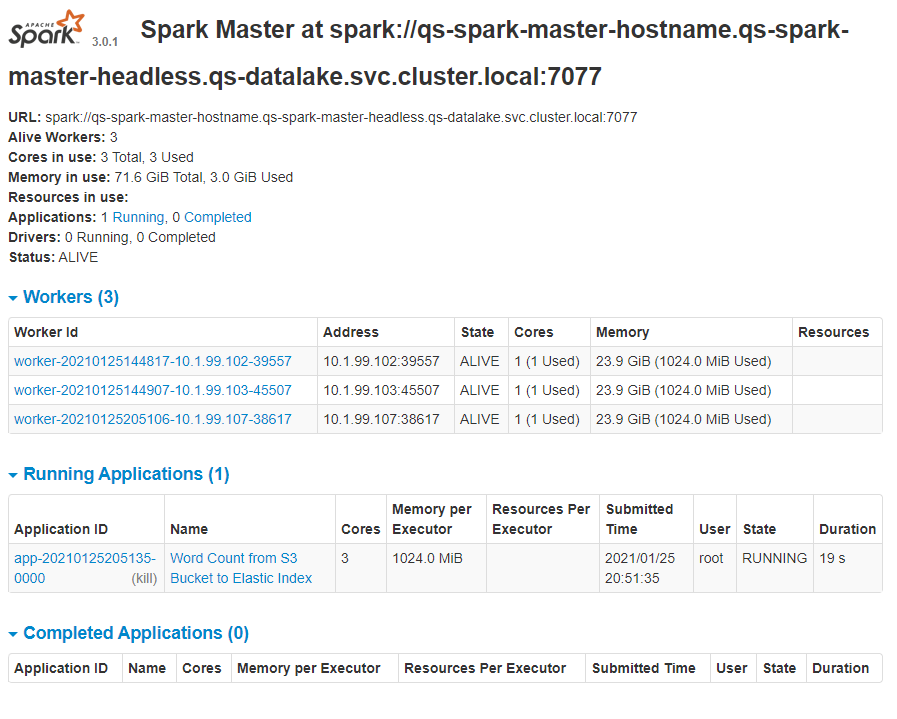
Bei Klick auf die laufende Application, lässt sich auch nachweisen, dass die verteilte Abarbeitung der Application unter Einbeziehung aller 3 Worker korrekt funktioniert. Die in dem folgenden Screenshot gelb markierten Worker-IDs entsprechen genau den Worker-IDs des vorherigen Screenshots. Beim Worker mit der ID „worker-20210125205106-10.1.99.107-38617“ handelt es sich um den dynamischen zeitgesteuerten Worker der auf Basis des Kubernetes Cronjobs innerhalb des Kubernetes Pods erzeugt wurde. Dieser „Job-Pod“ wird nach dem Abarbeiten der Application von Kubernetes automatisch beendet und auf „Completed“ gesetzt. Aus diesem Grund erscheint er auch im folgenden Screenshot unter „Removed Executors“. Die zwei anderen Executors wurden ebenfalls entfernt, weil sie offensichtlich in direkter Verbindung mit dem „gelöschten“ Executor aus unserem dynamisch erzeugten Worker standen.
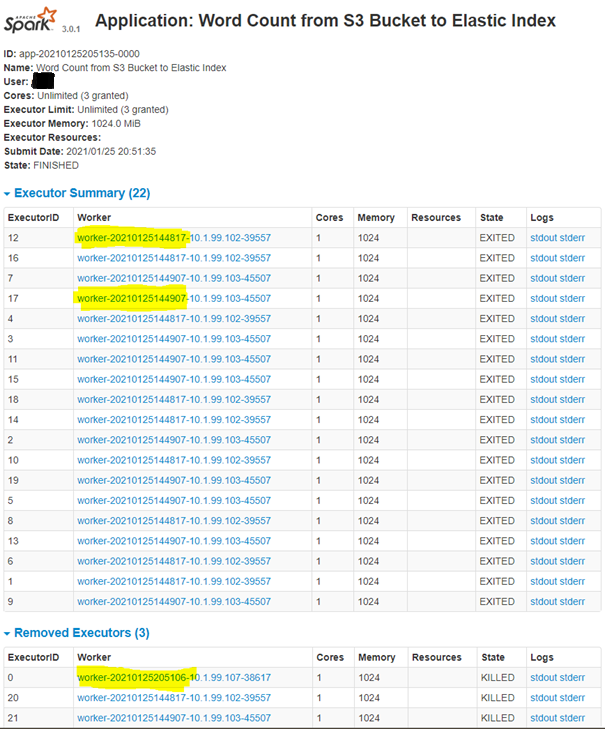
Die dynamisch erzeugten Worker werden nach Ablauf des Kubernetes Cronjobs im folgenden Screenshot der Spark Web-UI zwar noch angezeigt allerdings korrekterweise mit dem State „DEAD“ vermerkt. Dies ist unser gewünschtes Verhalten des Gesamt-Szenarios. Im unteren Teil des Screenshots stellt sich dar, dass unsere übermittelte Application unter Zuhilfename des dynamischen Workers jeweils korrekt mit dem State „FINISHED“ beendet wurde. Anhand der „Submitted Time“ wird ebenfalls deutlich, dass unsere Application, wie in der Kubernetes CronJob Konfiguration eingestellt, exakt jede Minute angelaufen ist (+/- ein paar Sekunden).
Fazit: Apache Spark Scheduling mit Kubernetes
Mit Kubernetes Cronjobs lassen sich Spark Applications sehr gut zeitgesteuert ausführen. Dabei wird als positiver Nebeneffekt der Spark-Verbund von Master und Worker Knoten zusätzlich durch Hochfahren eines Worker-Pods verstärkt. Wichtig bei der Konfiguration des Containers innerhalb des zeitgesteuerten Worker-Pods ist die Einhaltung der Reihenfolge der Kommandos (Property „command“ im YAML-File). Natürlich ist es auch möglich einen konventionellen Kubernetes Job zu entwerfen und diesen beispielsweise über einen API-Request oder innerhalb einer Data-Pipeline manuell bzw. auf Basis eines Events im Sinne von DataOps zu triggern.
Unser vollständiges Szenario beinhaltet zudem die Konfiguration der Verbindungen zum Object Storage MINIO sowie zur Search-Engine Elasticsearch inklusiver der Konfiguration und Bekanntmachung der benötigten SSL-Zertifikate der angebundenen System über das Java Keytool innerhalb von Apache Spark. Bei Interesse an unseren Cloud-basierten Big Data Services oder falls Sie Unterstützung beim Aufbau einer Big Data Infrastruktur benötigen, nehmen Sie gerne Kontakt mit uns auf.
Author: Marco Kittel
Quellen:
- https://kubernetes.io
- https://spark.apache.org
- https://scala-lang.org
- https://www.python.org
- https://docs.databricks.com
- https://www.tensorflow.org
- https://kafka.apache.org
- https://mesos.apache.org
- https://www.tensorflow.org
- https://bitnami.com
- https://en.wikipedia.org
- https://min.io
- https://docs.oracle.com
- https://www.elastic.co